sd-webui-controlnet
Github: https://github.com/Mikubill/sd-webui-controlnet
ControlNet就是用来控制构图的。可以控制Stable Diffusion,以支持额外的输入条件。ControlNet以端到端方式学习特定任务的条件输入,即使训练数据集很小(< 50k),效果也很健壮。
训练ControlNet的速度与微调 Stable Diffusion 一样快,而且该模型可以在个人设备上训练。如果强大的计算集群可用,该模型可以扩展到大量(数百万到数十亿)的数据。
论文表明,像Stable Diffusion这样的大型扩散模型可以用ControlNet来增强,以支持像边缘map、分割map、关键点等条件输入。这将丰富大型扩散模型的控制方法,并进一步促进相关应用:
参考:
https://www.datalearner.com/ai-resources/ai-paper-news/1051678531247530
sd_dreambooth_extension
Github: https://github.com/d8ahazard/sd_dreambooth_extension
DreamBooth是谷歌推出的一个主题驱动的AI生成模型,它可以微调文本到图像扩散模型或新图像的结果。Dreambooth可以做一些其他扩散模型不能或者不擅长的事情,比如DALL-E 2、Midjourney以及Stable Diffusion等模型都对主题缺乏情景化。
Dreambooth具备个性化结果的能力,既包括文本到图像模型生成的结果,也包括用户输入的任何图片。
参考:
https://dreambooth.github.io/
sd-webui-roop
Github: https://github.com/s0md3v/sd-webui-roop
基于 roop 的换脸插件,只需提供一张照片即可。之前使用 SD 进行换脸一般使用 Lora 进行微调,
sd-webui-lobe-theme
Github: https://github.com/canisminor1990/sd-webui-lobe-theme
高定 Stable Diffusion 现代主题,UI上做了大量体验优化。
sd-webui-regional-prompter
Github: https://github.com/hako-mikan/sd-webui-regional-prompter
能够将画布分割,在不同区域指定不同关键词

stable-diffusion-webui-images-browser
Github: https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
图片浏览器,可以浏览删除生成的图片,查看生成的信息,还有收藏夹功能。
可以将该信息发送到 txt2img、img2img 等。
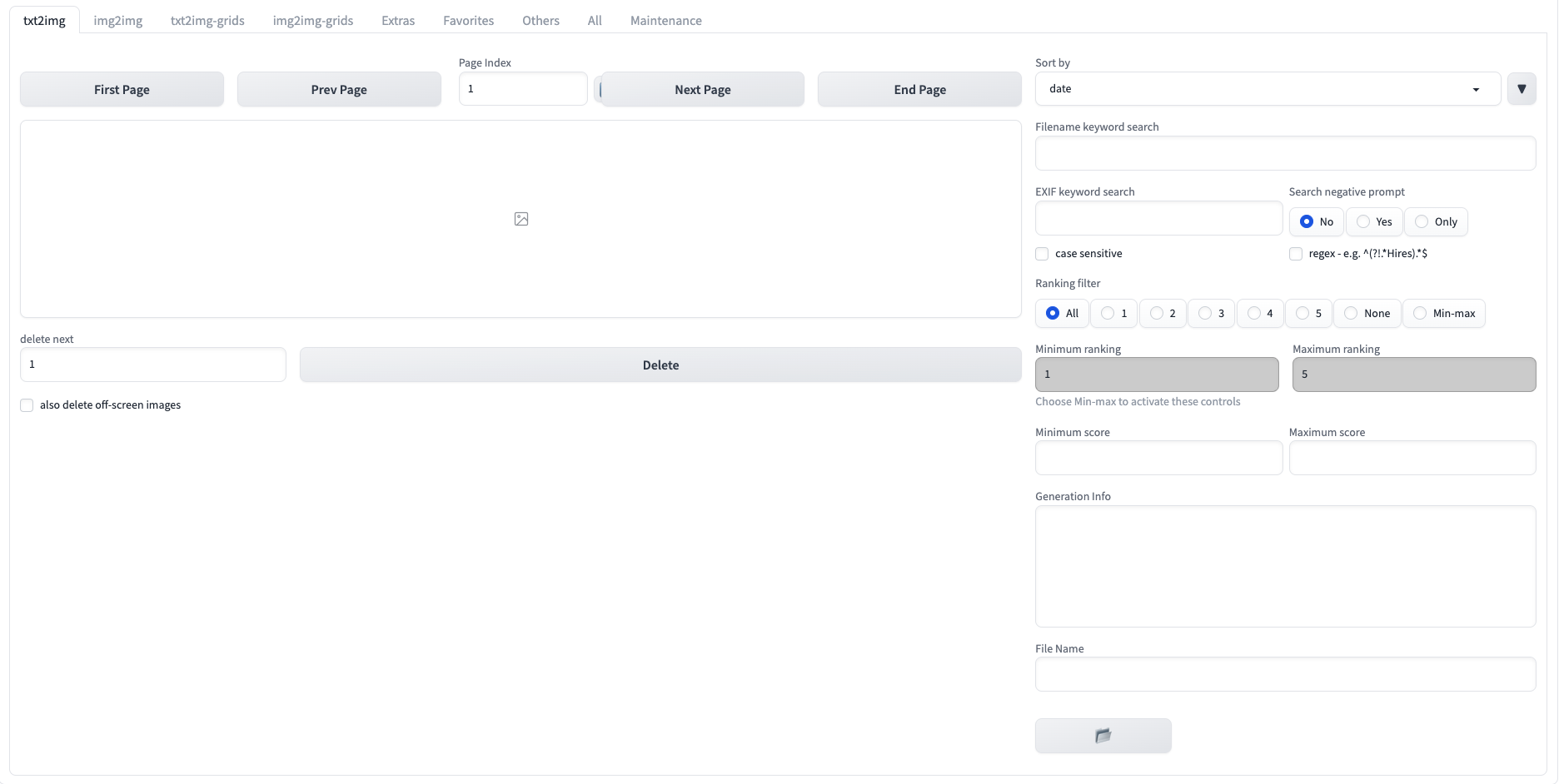
stable-diffusion-webui-wd14-tagger
Github: https://github.com/picobyte/stable-diffusion-webui-wd14-tagger
反推提示词插件,反推AI生成的图,进行重现信息。
当看到别人画的图,按照他提供的 prompt 以及模型根本无法复现。有时候甚至连 prompt 都没提供,凭自己的想象力很难用合适的提示词来描述这个画面,可以使用 tagger 反推提示词