最近,Stability AI正式推出了全新的SDXL 1.0版本。与1.5版本相比,SDXL的效果有了巨大的提升。不仅在理解提示词方面表现出色,而且图片的构图、颜色渲染和画面细腻程度都有了很大的进步,实际出图效果堪比Midjourney!
SDXL 1.0具有以下新特性:
- 更好的成像质量:SDXL能够以几乎任何艺术风格生成高质量的图像,SDXL 1.0比SD v1.5和SD v2.1(甚至比SDXL 0.9)都有巨大的提升!盲测者评估图像在各种风格、概念和类别中的整体质量和美学都是最好的。
- 更多艺术风格:SDXL v1.0比其前身能够实现更多的风格,并且对每种风格都“知道”得更多。您可以尝试比以前更多的艺术家名称和美学。SDXL 1.0特别适合生动、准确的颜色,比其前身具有更好的对比度、光照和阴影,质量可与Midjourney的最新版本相媲美。
- 更智能、更简单的语言:SDXL只需要几个词就能创建复杂、详细、美观的图像。用户不再需要调用“杰作”等限定词来获得高质量图像。此外,SDXL能够理解诸如“红场”(一个著名的地方)与“红色正方形”(一个形状)之间的概念差异。
- 更高的分辨率:SDXL 1.0的基础分辨率为1024 x 1024,比其前身产生了更好的图像细节,同时SDXL 1.0处理宽高比效果更好。
- 最大的开放图像模型:SDXL 1.0拥有任何开源文生图模型中最大的参数数量之一,它建立在一个创新的新架构上,由一个3.5B参数基础模型和一个6.6B参数精炼器组成。完整模型由一个专家混合管道组成,用于潜在扩散:
- 微调和高级控制:使用SDXL 1.0,微调模型以适应自定义数据比以往更容易。可以使用更少的数据整理来生成自定义LoRAs或检查点。Stability AI团队正在构建T2I/ControlNet专门针对SDXL构建下一代的特定任务结构、样式和组成控制。
SDXL 1.0包括两种不同的模型:
sdxl-base-1.0:生成1024 x 1024图像的基本文本到图像模型。基本模型使用OpenCLIP-ViT/G和CLIP-ViT/L进行文本编码。
sdxl-refiner-1.0:一个图像到图像的模型,用于细化基本模型的潜在输出,可以生成更高保真度的图像。细化模型只使用OpenCLIP-ViT/G模型。
SDXL 1.0的refiner是基于OpenCLIP-ViT/G的具有6.6B参数模是目前可用的最强大的开放访问图像模型之一。
base模型在第一阶段创建(有噪声的)结果,然后由专门为最后去噪步骤设计的refiner模型进一步处理(base模型也可以作为一个模块单独使用)
水印
SDXL 1.0内置不可见水印功能。如果输入不正确(接受BGR而不是RGB作为输入),水印特性有时会导致不想要的图像伪影。
在使用某些调度器和VAE (0.9 vs 1.0)时,生成的图像中可能会产生问题。但是其中一些问题的原因是已知,所以将来可能会修复。
另外水印这个事会让鉴别更加简单,依靠AI生成内容的行业可能会有很大的影响。
0.9 与 1.0区别
Stable Diffusion WebUI 1.5.0 版本以上才支持 SDXL,使用前请查看 SD WebUI 版本。
同时 SDXL 对显存要求更高了,确保你的 GPU 至少有 8 GB 以上显存。
SDXL 模型分2个: base 和 refiner
VAE 下载:https://huggingface.co/stabilityai/sdxl-vae/resolve/main/sdxl_vae.safetensors
base 及 refiner 模型放在 models/Stable-diffusion 目录下,sdxl_vae 放在 models/VAE 目录下。
基本使用
Stable-Diffusion-WebUI 从 1.5.1 版本开始支持 SDXL。
选择 sd_xl_base_1.0 模型,填写如下提示词
Prompt: 1 girl
注意,要分辨率改为 1024 ,否则出来的图很抽象,像这样:

其他参数保持默认,点击 Genarate。
可以看到在非常少提示词且没有反向提示词的情况下,SDXL 已经可以生成质量不错的图片了,比 SD2.0 有很大进步。
使用 Refiner
SD WebUI 截至1.5.1版本,在使用 base 模型生成图片后,需要将图片发送到图生图,再切换 refiner 模型。
如果想一步直接使用 Refiner ,可以安装插件:https://github.com/wcde/sd-webui-refiner
在 txt2img 中,如下图所示选择 refiner 模型,并激活扩展
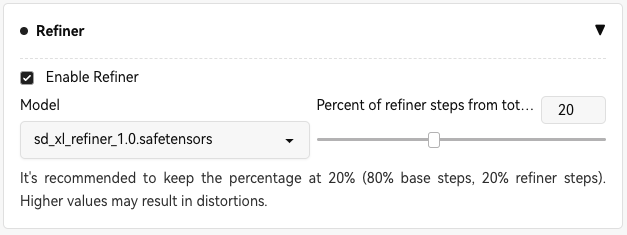
再点击 Generate,对比只使用 base 生成的图,可以看到 refiner 后图片细节更加丰富,质感更好。

使用 Lora
SDXL 目前支持Lora,(Refiner 模型可以单独使用,但目前不能加Lora,Base模型启用Refiner,可以使用Lora)
选择不同风格
SD WebUI 目前不能选择 SDXL 不同风格,可以安装扩展 Style Selector for SDXL 1.0 来支持。
Github: https://github.com/wcde/sd-webui-refiner
安装后如下图所示,选择 Enable Style Selector, 我们测试一下 Pop Art 风格
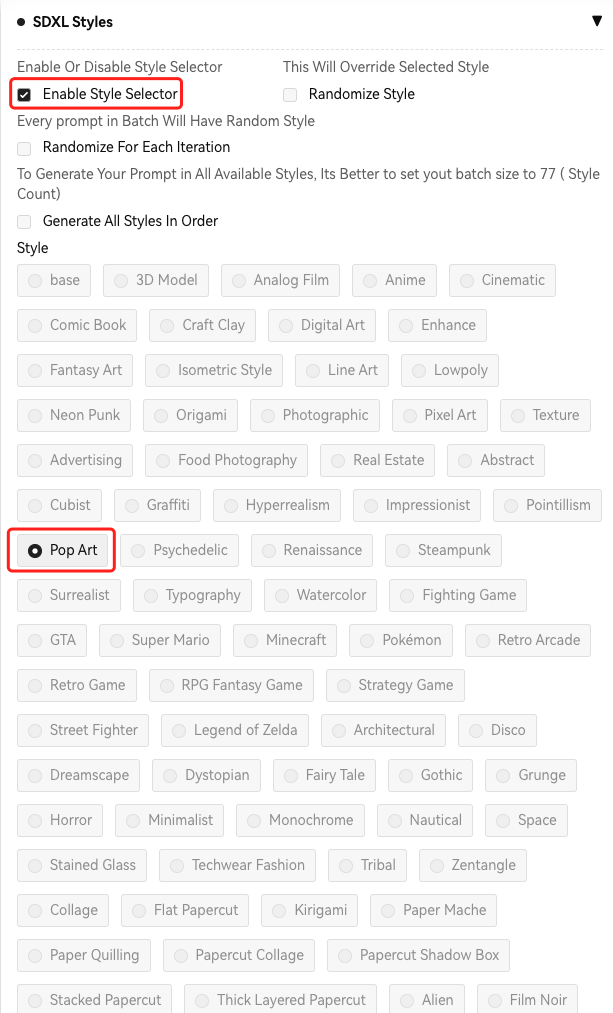
同时使用 Refiner, 点击 Generate。
