近年来,LLM(Large Language Model)取得了显著成功,并显示出了达到人类智能的巨大潜力。基于这种能力,使用LLM作为中央控制器来构建自助Agent,以获得类人决策能力。
Autonomous agents 又被称为智能体、Agent。指能够通过感知周围环境、进行规划以及执行动作来完成既定任务。
Agent 核心思想是为 LLM 配备记忆(Memory)和规划(Planning)等关键的人类能力,使其表现得像人类一样,并有效地完成各种任务。
LLM具有以问答 (QA) 形式完成各种任务的巨大潜力。然而,构建自主Agent与 QA 相去甚远,因为它们需要履行特定角色,并自主感知和学习环境,以像人类一样自我进化。为了弥合传统 LLM 和自主Agent之间的差距,一个关键是设计合理的Agent架构,以帮助 LLM 最大限度地发挥其能力。
大语言模型 Agent 主要分为4个模块:
Profile 模块的目的是标识Agent的角色。在Agent置于动态环境中,记忆(Memory)和规划(Planning)模块使其能够回忆过去的行为(Action)并规划未来的行动(Action)。动作模块负责将Agent的决策转化为具体的输出。在这些模块中,Profile模块影响记忆(Memory)和规划(Planning)模块,而这三个模块共同影响行动(Action)模块。下面,我们将详细介绍这些模块。
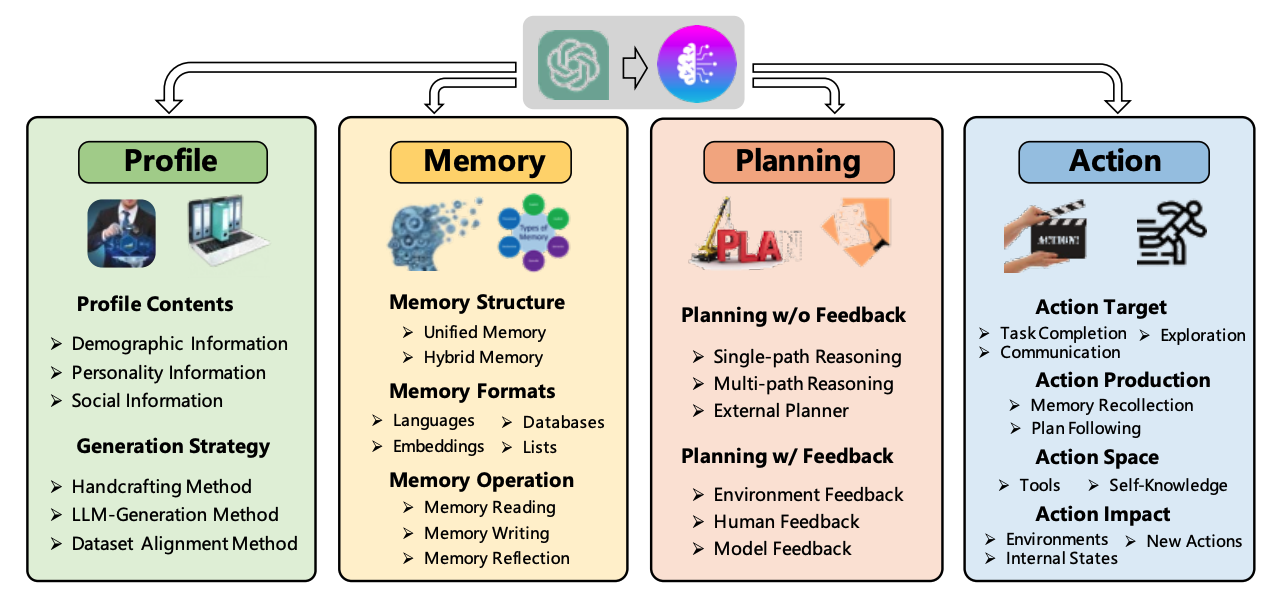
1、Profile
描述 Agent 的角色信息
(1)画像内容,主要基于 3 种信息:人口统计信息、个性信息和社交信息。
(2)生成策略:主要采用 3 种策略来生成画像内容:
- 手工设计方法:自行通过指定的方式,将用户画像的内容写入大模型的 prompt 中;适用于 Agent 数量比较少的情况;
- 大模型生成方法:首先指定少量画像,并将其作为示例,进而使用大语言模型生成更多的画像;适用于大量 Agent 的情况;
数据对齐方法:需要根据事先指定的数据集中人物的背景信息作为大语言模型的 prompt,进而做相应的预测。
2、Memory
存储从环境中感知到的信息,并利用记录的记忆来指引后面的Action。记忆模块可以帮助Agent积累经验、自我进化,并以更一致、更合理、更有效的方式行事。
(1)记忆结构
人类记忆遵循从暂时保存信息的短期记忆,再到长期记忆的一般发展过程。
短期记忆LLM上下文窗口内的输入信息。长期记忆类似于Agent可以根据需要快速查询和检索的外部存储。
- 统一记忆:模拟人类短期记忆,不考虑长期记忆;记忆内容在对话上下中,或在Prompt中将所有信息全部提供。例如与用户对话中用户提供的信息,及长文档理解等。但LLM上下文窗口有限制,可以使用混全记忆
- 混合记忆:短期记忆和长期记忆相结合。一般短期记忆包含有关Agent当前情况的上下文信息,而长期记忆(例如知识库)存储Agent过去的行为和想法,可根据当前query进行检索。
(2)记忆形式:主要基于以下 4 种形式
- 自然语言:记忆信息(例如Agent的Action和Observations)直接使用原始自然语言描述。这样有2个优点:1. 记忆信息可以以灵活且易于理解的方式表达,2. 它保留了丰富的语义信息,可以提供全面的信号来指导Agent 执行Action。
- 向量表示(Embeddings):记忆信息被编码成向量,提高记忆检索效率,例如将对话历史编码成向量以供检索。
- 数据库:记忆信息存储在数据库中,Agent可以通过LLM生成SQL直接查询数据库。
- 结构化列表(Structured Lists):例如树结构、三元组短语(triplet phrases)等。
- 当然,记忆还有其形式,不同形式还可以进行组合。
(3)记忆内容:常见以下 3 种操作:
- 记忆读取:例如对历史记录进行总结,提取有用的信息。
- 记忆写入:将有关感知环境的信息存储在记忆中。为将来检索信息记忆提供了基础,使代理能够更有效、更合理地采取行动。在记忆写入过程中,有两个潜在问题需要仔细解决。1. 解决如何存储与现有记忆相似的信息(即记忆重复)。需要采用各种方法来整合新的和以前的记录,例如:计数累积来聚合重复信息,避免冗余存储。2. 当内存达到其存储限制时,如何删除信息。例如,可以根据用户命令明确删除内存或使用固定大小的内存缓冲区,以先进先出 (FIFO) 的方式覆盖最旧的记忆。
- 记忆反射:模拟人类见证和评估自身认知、情感和行为过程的能力。例如,Agent能够将其存储在记忆中的过去经验总结为更广泛、更抽象的信息。
如果我们将记忆模块视为负责管理代理过去行为的模块,那么拥有另一个能够帮助代理规划未来行动的重要模块就变得至关重要。
3、Planning
当面对复杂任务时,人类倾向于将其分解为更简单的子任务并单独解决。规划模块旨在赋予智能体这种能力。
- 无需反馈的规划:大语言模型在做推理的过程中无需外界环境的反馈。这类规划进一步细分为三种类型:基于单路的推理,仅使用一次大语言模型就可以完整输出推理的步骤;基于多路的推理,借鉴众包的思想,让大语言模型生成多个推理路径,进而确定最佳路径;借用外部的规划器。
- 单路径推理。任务分解为几个中间步骤,以级联方式连接,每个步骤仅一个后续步骤。例如思维链 (CoT),将解决复杂问题的推理步骤输入到提示中。这些步骤作为示例,以启发 LLM 逐步规划和行动。在这种方法中,计划是根据提示中示例的启发创建的。
- 多路径推理:生成最终计划的推理步骤被组织成树状结构。每个中间步骤可能有多个后续步骤。这种方法类似于人类思维。例如思维树(ToT),使用树状推理结构生成计划。在这种方法中,树中的每个节点代表一个“思想”,它对应于一个中间推理步骤。这些中间步骤的选择基于 LLM 的评估。使用广度优先搜索 (BFS) 或深度优先搜索 (DFS) 策略生成最终计划。与同时生成所有计划步骤的 CoT-SC 相比,ToT 需要为每个推理步骤查询 LLM。
- 外部规划器:尽管 LLM 在零样本规划方面表现出色,但为特定领域问题生成规划仍然极具挑战性。例如,首先将任务描述转换为正式的规划领域定义语言 (PDDL),然后使用外部规划器处理 PDDL。最后,生成的结果由 LLM 转换回自然语言。
- 带有反馈的规划:在许多现实场景中,智能体需要进行长远规划来解决复杂的任务。面对这些任务时,上述没有反馈的规划模块可能会因为以下原因而变得不那么有效:首先,从一开始就直接生成一个完美的计划极其困难,因为它需要考虑各种复杂的先决条件。因此,简单地遵循初始计划往往会导致失败。此外,不可预测的过渡动态可能会阻碍计划的执行,导致初始计划无法执行。这种规划方式需要外界环境提供反馈,而大语言模型需要基于环境的反馈进行下一步以及后续的规划。这类规划反馈的提供者来自三个方面:环境反馈、人类反馈和模型反馈。
- 环境反馈。这种反馈来自客观世界或虚拟环境。例如,ReAct 提出使用思想-行为观察三元组构建提示。思想部分旨在促进指导代理行为的高级推理和规划。行为代表代理采取的特定行动。观察对应于通过外部反馈(例如搜索引擎结果)获得的动作结果。下一个想法受到先前观察的影响,这使得生成的计划更适应环境。
- 人类反馈。除了从环境中获取反馈外,直接与人类互动也是增强代理规划能力的一种非常直观的策略。人类反馈是一种主观信号。
- 模型反馈。代理本身的内部反馈。例如,自我改进机制。该机制由三个关键部分组成:输出、反馈和改进。首先,代理生成输出。然后,它利用 LLM 对输出提供反馈并提供如何改进它的指导。最后,通过反馈和改进改进输出。这个输出反馈改进过程不断迭代,直到达到某些期望条件。
4、Action
负责将Agent的决策转换为具体的输出或结果,该模块直接与环境交互。
-
动作目标:有些 Agent 的目标是完成某个任务,例如搜索查询天气或定外卖;有些是交流,例如与其他Agent沟通,共享信息,共同完成任务或与人类交流,并根据人类的反馈调整其行动策略;有些是探索,在探索不熟悉的环境以扩展其感知能力,并在探索和利用之间取得平衡。
-
动作生成:有些 Agent 是依靠记忆回想生成动作,有些是按照原有计划执行特定的动作。
通过记忆回忆的动作。在此策略中,动作是通过根据当前任务从Agent记忆中提取信息来生成的。任务和提取的记忆被用作触发代理动作的提示。例如,在生成代理[20]中,代理维护一个记忆流,在采取每个动作之前,它会从记忆流中检索最近的、相关的和重要的信息来指导代理动作。 -
动作空间:动作空间是指代理可以执行的一组可能的动作。
一般来说,我们可以粗略地将这些动作分为两类:(1)外部工具和(2)LLM 的内部知识。
外部工具。- API:例如网页爬虫、代码执行器、计算器、单位转换器、日历、地图、图表等。
数据库和知识库。集成外部数据库或知识库使代理能够获取特定领域的信息,从而生成更现实的操作。
外部模型。利用外部模型来扩展可能的操作范围。与 API 相比,外部模型通常处理更复杂的任务。每个外部模型可能对应多个 API。例如用于视频摘要的 VideoBERT、用于图像生成的 X-decoder 和用于音频处理的 SpeechBERT,增强在多种多模态场景中的能力。 - 内部知识。依赖 LLM 的内部知识来指导其行动。(1)规划能力。(2)对话能力。(3)常识理解能力。
- API:例如网页爬虫、代码执行器、计算器、单位转换器、日历、地图、图表等。
-
动作影响:包括对环境的影响(订外卖)、对内在状态的影响(例如更新记忆),以及对未来新动作的影响(例如触发新的Action)。